CS188-P1 Searching
前言
在本科学习的这两年里,深度学习、神经网络这些词汇不断地涌入视线。虽然我也看了很多科普文章想要一探它们的虚实,但始终没能对“人工智能”这个概念祛魅。
曾经有一位好友问我是否相信强人工智能终会实现,彼时的我对此一无所知,只是凭感觉认为计算这一运动终究无法产生理性或自由意志,现在的人工智能无非是利用数据和统计学的经验主义罢了。然而,随着阅读量的增加,我对之前这个幼稚的答案产生怀疑,我想探一探到底什么是人工智能?现在的深度学习在人工智能浪潮中扮演着什么角色?所谓的调参、炼丹到底是怎么回事?
为此,我选择阅读《Artificial Intelligence: A Modern Approach》。这本书对人工智能进行了全面而细致的介绍,从人工智能的缘起发展到最新的技术,确可一探人工智能全貌。与此同时,为了检验自己的学习成果,我还将同步跟进UC Berkerly的CS188课程,其中的Notes和Projects确为深入浅出,值得学习。
本节对应《现代方法》一书的前三章和cs188的project 1
什么是人工智能?
这本书在一开始就为这个根本性的问题给予解答。作者从两个维度衡量人工智能,产生了四种不同的观点:
| like human | rationally | |
|---|---|---|
| thinking | 认知建模 | 思维法则 |
| acting | 图灵测试 | rational agent |
图灵测试:观察者抛出一些问题后,如果他不能区分答案是来自机器还是人就说明这台计算机通过了图灵测试。通过图灵测试的意义在于证明计算机能够acting like human. 然而,很少有工作者致力于这个方向的研究,因为acting like human并不是人类对人工智能的真正需求,正如飞行器的飞行动作不需要完全和鸟类一样。
认知建模:认知建模方法是为了让计算机thinking like human. 它的基本思想是完全搞清楚人类的思考过程,然后用计算机程序建模。这涉及神经科学、心理学等多个交叉学科的研究。
思维法则:亚里士多德提出的三段论开启了逻辑学的先河,thinking rationally要求计算机能够做出符合逻辑学原理的推断。然而,在逻辑的世界中一切知识都必须是确定的,事实上现实世界很难满足这一条件,概率论则弥补了这一缺陷,使得逻辑流派的AI能够从充满不确定性的感知信息中推断甚至预测未来。
Rational agent:Agent: 有行为的实体,包括感知环境、自动地操作、适应变化等。Rational Agent: 为了实现最佳结果而行动的实体。这种方式的AI相比思维法则更有优势,因为:
- Think rationally只是实现理性的方式之一
- 更经得起科学发展的检验,因为rationality在数学上是well-defined的
现在AI发展的主流就是构建do the right thing的agent,主要基于机器学习和概率论的方法。
Searching: Theory
TBD
Searching: Coding(cs188 project1)
Q1: Depth First Search
Q2: Breadth First Search
Q3: Uniform Cost Search
Q4: Astar Search
这四个问题都可抽象出以下函数,不同的只是fringe的具体数据结构。

在Python中的具体实现如下:
1 | def genericSearch(problem, container, argFunc): |
值得注意的是,虽然不同数据结构(Stack, Queue, PriorityQueue)所暴露的接口名都是一样的:push()和pop()。但PriorityQueue在push时还需要传入priority参数即push(item, priority),而Stack和Queue的函数签名为push(item, priority)。
为了解决这个问题,可以在genericSearch中传入push()的参数生成函数,然后利用Python方便的push(**func)传参语法,这样就保持了接口的统一。
具体调用如下:
1 | def depthFirstSearch(problem): |
Q5 Corners Problem: Representation
这道题目要求为Corners Problem确定合适的State表示,既需要能区分不同状态又要尽量精简防止状态空间过大。我的实现如下:
1 | (position, hasVisited) |
Q6 Corners Problem: Heuristic
这道题目要为Q5中的Corners Problem编写启发式搜索规则。
一开始我的想法是一个点越早能到达Corners中的一个优先级越高(即currentPosition到所有corners距离的最小值作为启发函数返回值),但结果还是需要expand 1500+次,效果一般。
仔细考虑这个问题,一旦Picman到达Corners中的任意一个,记为$C$,这个问题就被归约成了$C$到达其它三个角落所需要的时间。而$C$一共只有4个取值,我们完全可以先把这些小规模问题解决了,然后再解决如何归约的问题。
一共四个顶点,两两之间有边,求从任意顶点出发经历所有顶点的最短路径
这其实就类似旅行商问题,但由于$N=4$,即使是阶乘复杂度也能接受。
最后我们的启发函数返回如下:当前所在位置currentPosition, 计算到每个corner的曼哈顿距离和该corner的最短遍历距离,取最小值返回:
1 | sortedManDist = [abs(currentPos[0] - c[0]) + abs(currentPos[1] - c[1]) + shortestPaths(visit)[corners.index(c)] for c in corners] |
想法很美好,实际运算也很快:只expand了311次就完成了最佳路径的搜索,远超过了这道题要求的最优水平

结果在autograder上报错:这个启发函数并不具有一致性。首先容易证明上述启发函数Admissible,因为一次位移只会带来曼哈顿距离部分的变化,最多为1. 而一致性要求任意两个状态的启发值之差要≤状态转移需要的cost。考虑如下场景:
%%%%%%%% %%%%%%%%
%.% .% %.% P%
% % % P% % % % %
% % % % % % % %
% % % -> % % %
%%%%% % %%%%% %
% % % %
%%%%%%%% %%%%%%%%
在左图中只剩下顶角的两个corner未被访问,根据我们的启发函数,左图的启发值应该是P到右上角的曼哈顿距离(1) + 左右两corner之间的实际距离(假设11), 即12. 而一旦到了右图,只剩下左上角一个点未被访问,P到左上角的曼哈顿距离(5) + 左上角开始访问所有剩下顶点的距离和(0),即5.. 两个启发函数之间的差值瞬间变大。
其原因在于,在计算currentPosition到corner的距离时,我们用曼哈顿距离做近似;而在计算corner之间的遍历距离时,我们用了真实值。这两者混合在一起就会产生上述谬误。为了解决,我在计算各corner之间的遍历距离时也采用曼哈顿距离,最终优化结果还不错:

上述错误实际反应了我们在应用启发式搜索时的一个启发式原则(谜语人:)
启发式规则尽量是real problem的relaxed版本的答案
比如在这道题中,如果都采用曼哈顿距离那这个启发规则就是无围墙时的准确估计;而如果像之前那样混搭则不满足这个直觉想法
Q7: Eating All The Dots
这道题是要遍历所有food所在位置,是上一个问题的增强版。在这个问题中我们就没办法强行求解旅行商问题了,因为$N$取值会很大。
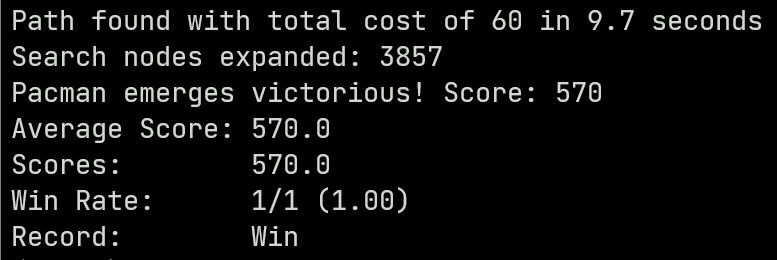
于是我就把几个常见的启发函数都试了一遍,比如到任意food的最短曼哈顿距离、最长曼哈顿距离、最短实际距离和最长实际距离。最终发现采用最长实际距离时效果很好(我还没能给出一个可靠的解释,待填坑)
1 | if len(foodList) == 0 : |
Q8:Suboptimal Search
这道题目本身只有一两行代码,但蕴含的道理很受用:有时候即使有一致的启发规则,A*算法运行起来还是很缓慢;如果此时我们对结果是否一定“最优”要求不高,但对效率要求很高希望能在较短时间内给出一个还算可以的结果时,就可以采用一些比较激进的优化策略来寻找次优解。
比如在Q7中,为了寻找最优解我们要么需要expand很多次,要么需要运行10s左右。但如果我们每次只找最近的food吃,最后结果也不会太差,效率却很高。
总结
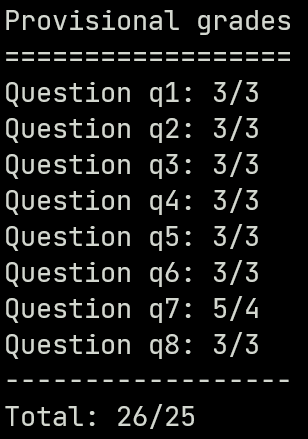
最终得分:
这次实验是对这几种搜索算法一个很不错的练习。尤其是Q6和Q7,在想启发规则来优化expand times时,还是很需要头脑风暴的,很有意思。可惜的是我没能给Q7一个完美的解释…希望之后能填坑。